algolia-docsearch
什么是文档搜索?
作为开发人员,我们花了很多时间阅读文档,在大型文档中很难找到相关信息。建立良好的搜索是一项挑战。
这里介绍一种免费开源,低成本接入的站点搜索接入方案--algolia DocSearch;
哪些网站在用algolia DocSearch
前端接入度搜索组件是这样的 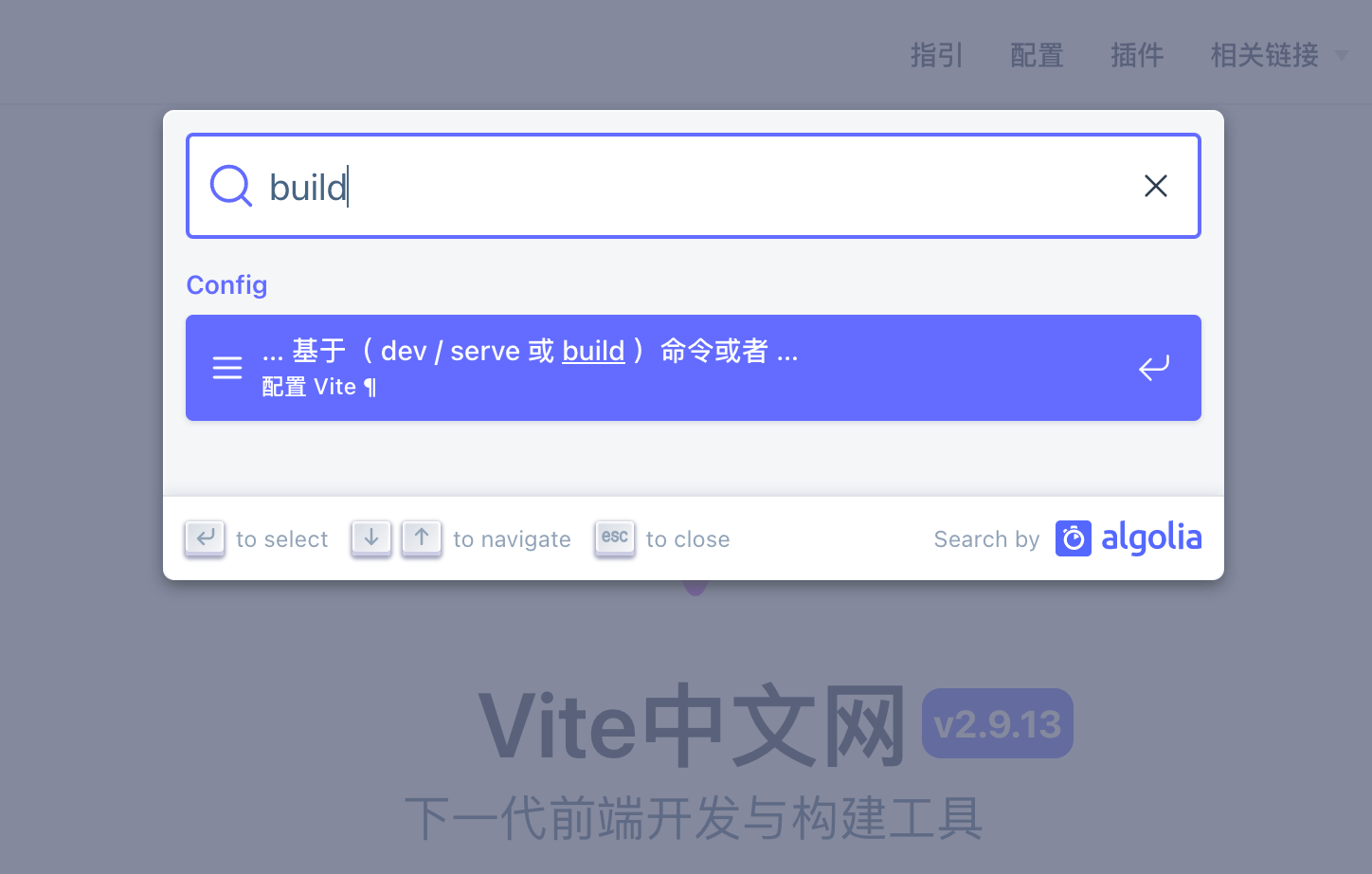
以下网站都在用,用了都说好~
algolia DocSearch
Algolia 是一个数据库实时搜索服务,能够提供毫秒级的数据库搜索服务,并且其服务能以 API 的形式方便地布局到网页、客户端、APP 等多种场景。 官网注册
以前注册时的界面是这样的:  现在注册界面是这样的:
现在注册界面是这样的: 
DocSearch 分为爬虫和前端库。
- 抓取由Algolia Crawler处理,默认情况下每周运行一次,然后您可以自己触发新的抓取并直接从Crawler界面监控它们,该界面还提供了一个实时编辑器,您可以在其中维护您的配置。
- 前端库建立在Algolia Autocomplete之上,并通过其模态提供身临其境的搜索体验。
备注
可能是因为免费用户,我并没有成功crawler管理后台上找到我的algolia注册的应用,所以爬虫这一块我是通过docker服务来爬数据上传到algolia Data Sources 数据库中的
实践流程记录
- 申请注册账户
- 新建应用
- 新建Indices 数据表
爬虫服务
这里直接使用docker
- 下载docker镜像 docker pull algolia/docsearch-scraper
- 根据配置启动dokcer爬虫服务 .env文件
.env文件
txt
APPLICATION_ID=YOUR_APPLICATION_ID
API_KEY=YOUR_API_KEY
1
2
2
config.json 以下配置只是demo,有些API已经变更或者废弃,请参考配置,新旧版本API废弃或者变更及配置参考文档
这里建议设置站点地图,会抓去更全面的网站,通过更新站点地图和设置action来定时调度,执行爬虫任务,更新索引数据。
js
{
"index_name": "Home",
"start_urls": [
"https://timesky.top/pick-mint/",
"https://timesky.top/pick-mint/program/server/node/esm.html",
"https://timesky.top/pick-mint/record/daily-record/record-2022.html"
],
"stop_urls": [],
"selectors": {
"lvl0": {
"selector": ".VPNavBarMenuLink",
"global": true,
"default_value": "Documentation"
},
"lvl1": ".VPLink .link-text, .main h1",
"lvl2": "h1, h2",
"lvl3": "h3",
"text": "p, li, code"
},
"js_render": true,
"js_wait": 4
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
执行一下命令,启动docker服务,注意文件路径
sh
docker run -it --env-file=你的文件路径/.env -e "CONFIG=$(cat 你的文件路径/config.json)" algolia/docsearch-scraper
1
比如在我的电脑中执行的sh命令是:
sh
docker run -it --env-file=/Users/liutao/workspace/timesky/algolia/dockConfig/.env -e "CONFIG=$(cat /Users/liutao/workspace/timesky/algolia/dockConfig/config.json)" algolia/docsearch-scraper
1
执行结果如下: 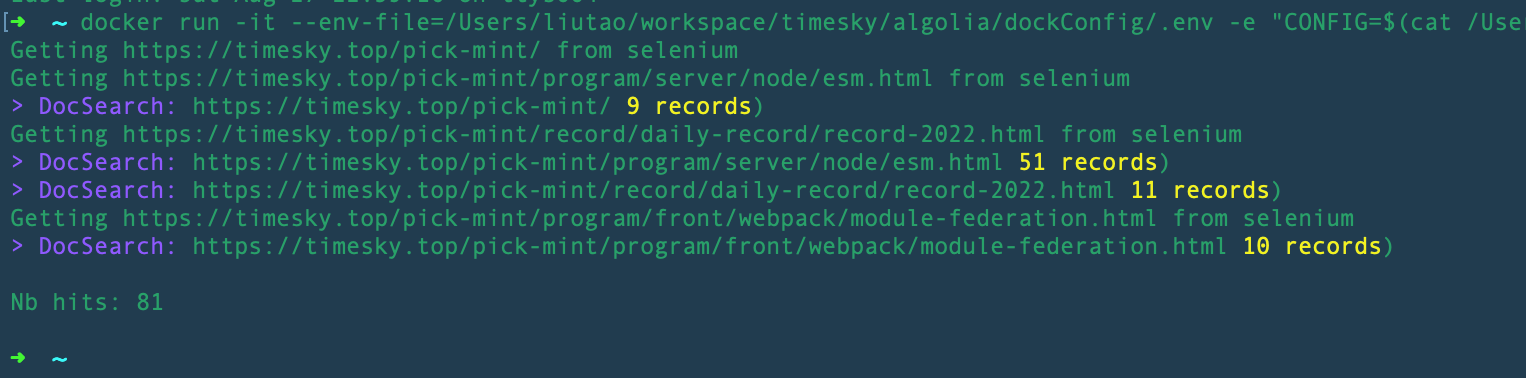 在官网查看数据库
在官网查看数据库 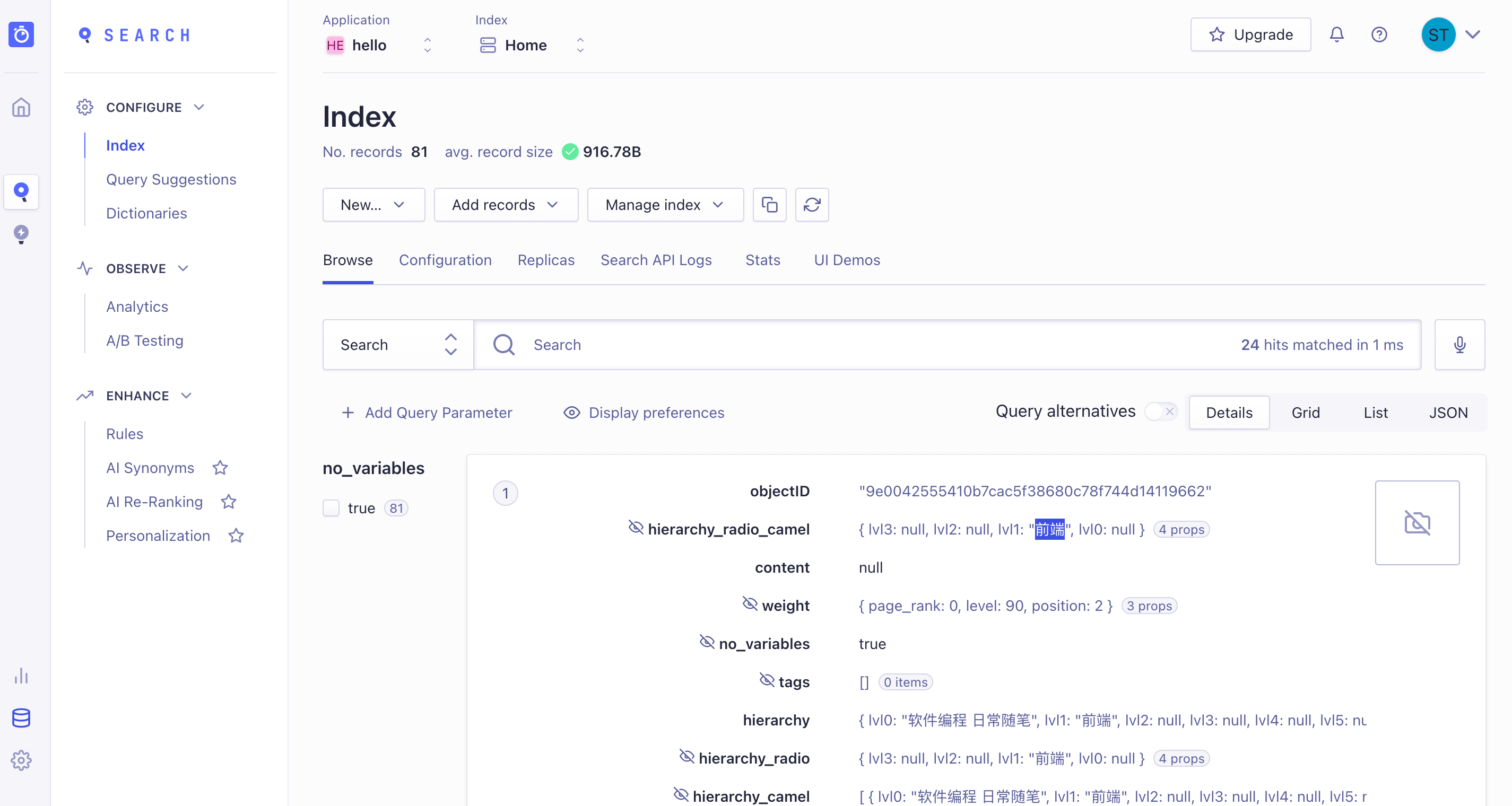
前端接入搜索框
像vitepress之类已经集成algolia的前端工具直接配置如下参数就可以了
js
{
appId: '',
apiKey: '',
indexName: ''
}
1
2
3
4
5
2
3
4
5
纯前端接入很简单,详细参考文档
- 如果是react框架 npm install @docsearch/react@3;
- 如果是其他框架 npm install @docsearch/js@3;
比如在react页面中:
js
import { DocSearch } from '@docsearch/react';
import '@docsearch/css';
function App() {
return (
<DocSearch
appId="YOUR_APP_ID"
indexName="YOUR_INDEX_NAME"
apiKey="YOUR_SEARCH_API_KEY"
/>
);
}
export default App;
1
2
3
4
5
6
7
8
9
10
11
12
2
3
4
5
6
7
8
9
10
11
12
比如在我的博客接入效果是这样 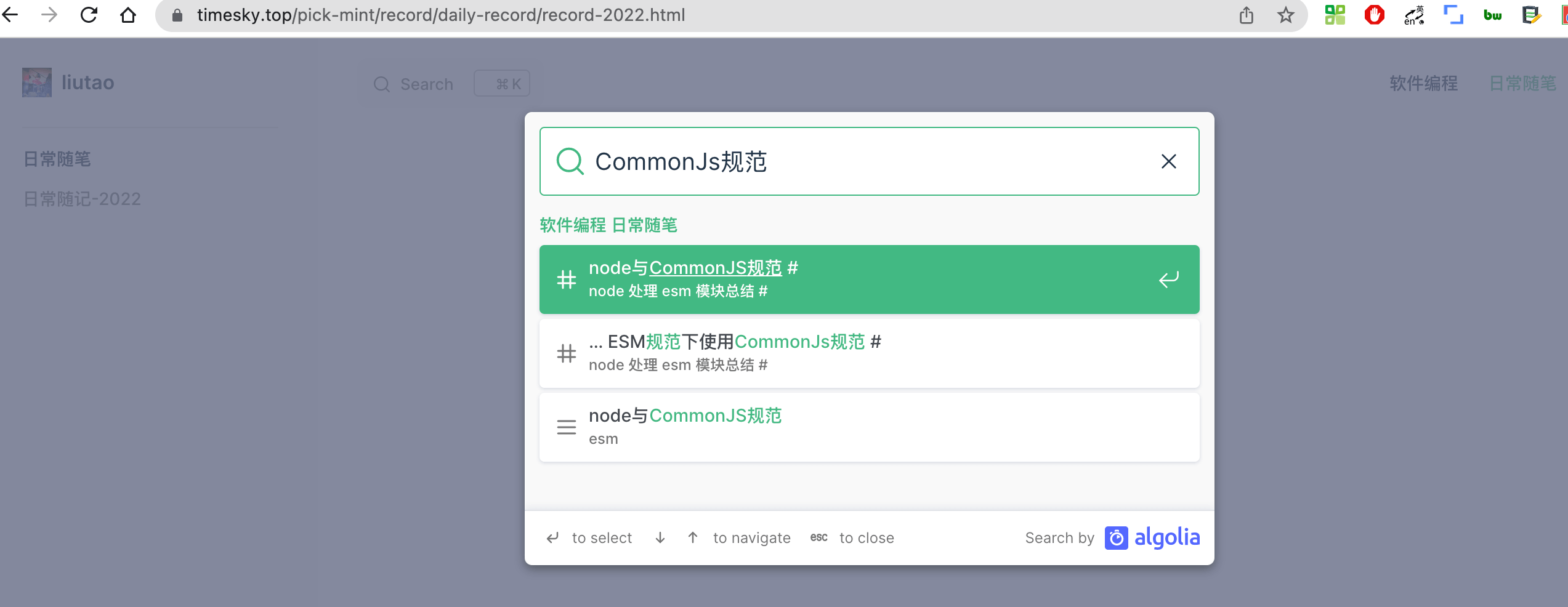
后续的工作模型设计
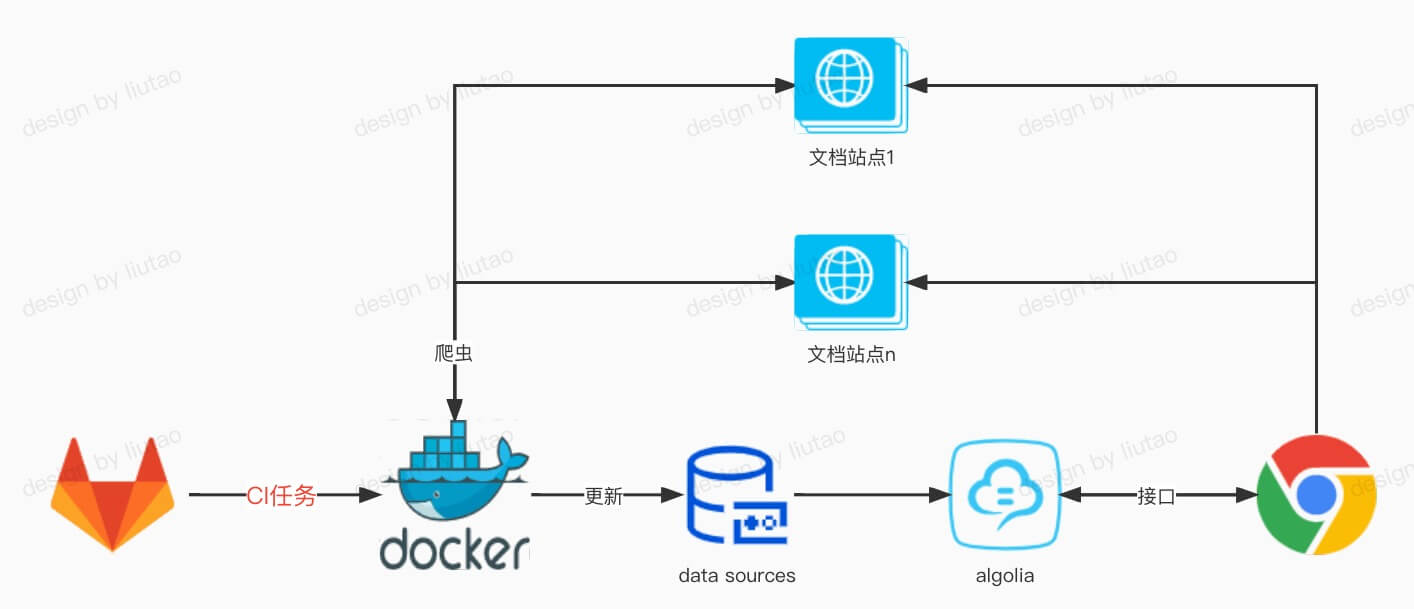
因为前端的组件库以及各个站点是动态维护的,所以后续爬虫需要根据更新做出事实更新和每日定时动态爬取更新数据库,所以设计了一个工作模型来维持数据库的实时更新。
可以利用我设计的模型用户企业的各种组件库文档的全站点搜索。
- docker的运行配置信息,文档站点导航信息维护在git端
- 文档发布后上传站点导航信息到git仓库触发git CI 工作流
- git CI执行 docker 爬虫任务,爬取配置站点导航相关网页信息,更新数据库信息
- 初次之外docker每天定时执行action任务
- 用户在浏览器网页搜索框输入关键字查询数据库信息,返回站点相关链接地址,用户点击记录访问站点
工作模型设计如下: